AI-Generated Subtitles Using Whisper

Disclaimer: Although I work for SPIEGEL-Verlag, this was a purely private project. I only chose SPIEGEL TV videos as an example because I really like their productions.
High-quality video content without subtitles? This will still be the case on many channels in 2024. Creating subtitles manually is likely to be very time-consuming, so let's try to use the power of AI to solve this problem in a timely manner.
"Around 80,000 people in Germany are deaf. Around 250,000 use German Sign Language, or DGS for short, including those who are hard of hearing and people with electronic hearing prostheses." (source)
All of these people have difficulties accessing information, education, and critical discussion in their daily lives - and let's face it, subtitling is not just about the deaf. Who doesn't enjoy watching an impressive video every once in a while instead of reading a text? Subtitles also help when learning languages in noisy environments or when headphones are not available in public places. In addition, users are now accustomed to subtitles as an integral part of video content on major social media platforms.
Public broadcasters are also getting involved in the topic of AI. It is considered an opportunity for more accessibility (and thus also the topic of subtitling), as the statements from ZDF (source) and ARD (source) show.
The Challenges
Speech-to-text has been around for a long time. Advances in artificial intelligence are now bringing it back into the spotlight, and exciting new developments are being made. In addition to correctly transcribing words from speech to text, the biggest challenge in automated subtitling is creating accurate timestamps. Even the best subtitles won't help if they don't match the content being spoken at that moment.
While providers such as Netflix often display subtitles in simplified and abbreviated language, the approaches taken here result in subtitles that are as close as possible to the transcription of the spoken language. This has the advantage that no content is lost or shortened - the reader is not disadvantaged compared to the listener. However, the logical disadvantage is that the displayed subtitles are longer than would be the case with a shortened form.
Best Practice of Subtitling
At this point, it makes sense to take a closer look at best practices for subtitles. While the BBC recommends 37 characters and a maximum of 2 lines (source), Netflix specifies 42 characters per subtitle line as the optimal value for most languages (source). I will use a maximum of two lines with 42 characters for my experiments. However, I think word-for-word subtitles might need a bit more length to be displayed long enough.
Using OpenAI Whisper for Transcription
For my experiments, I use the Whisper model from OpenAI (paper, website) as a basis, although this model alone cannot satisfy my requirements sufficiently and has to be combined with other approaches. Whisper offers a relatively low word error rate of about 5%, especially with the "large" model variants. There are many open source projects that build on top of Whisper and add additional pre- or post-processing capabilities.
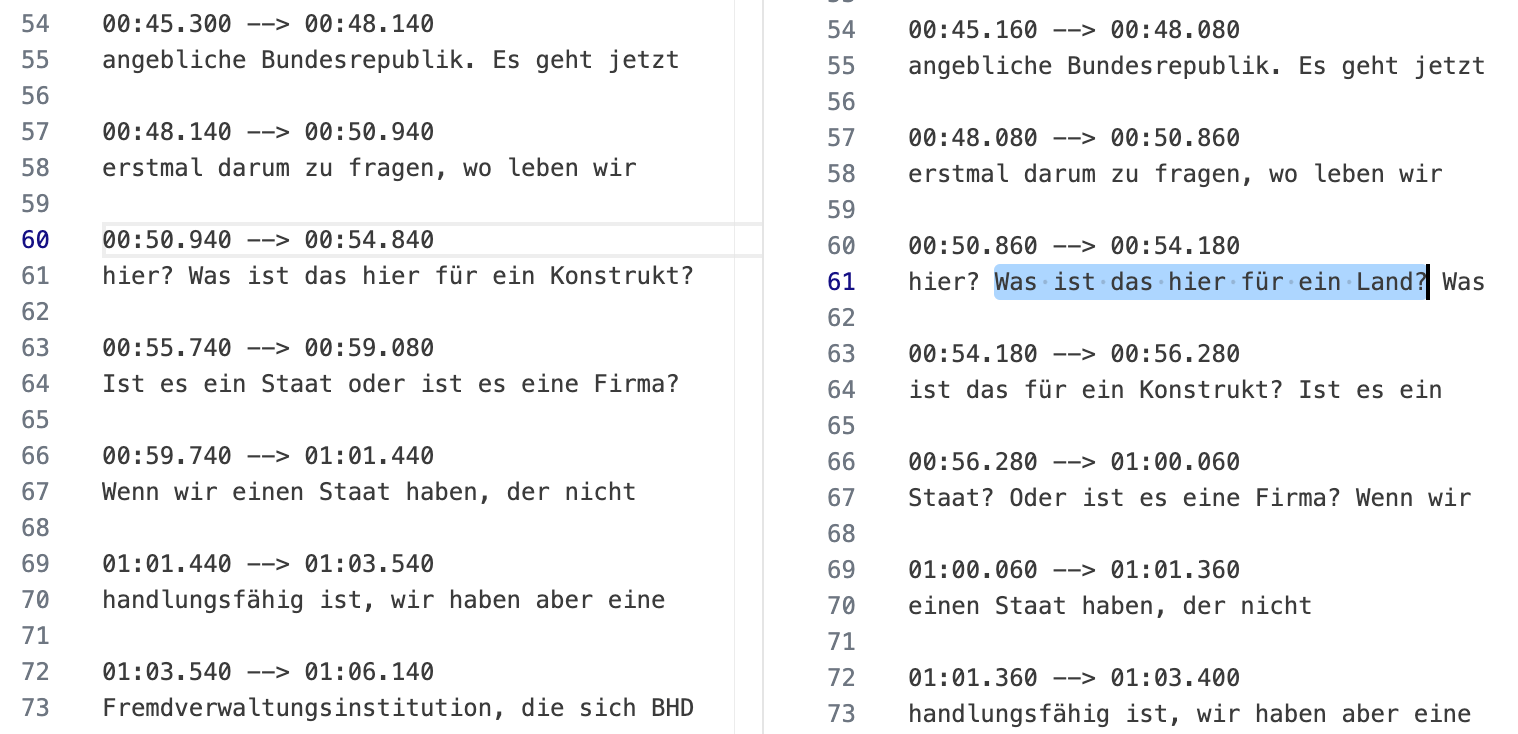
It is important to note that models like Whisper can also hallucinate. The following screenshot shows the large-v3 model hallucinating the sentence "Was ist das hier für ein Land?", which does not exist. Large-v2 did not produce this particular hallucination. Overall, I had the feeling that v2 hallucinated less in my trials.
They are a combination of failure modes of seq2seq models, language models, and text-audio alignment and include problems such as getting stuck in repeat loops, not transcribing the first or last few words of an audio segment, or complete hallucination where the model will output a transcript entirely unrelated to the actual audio. (source, page 14)
Countermeasures could be taken, such as using Voice Activity Detection (VAD) to avoid feeding the model audio sequences that do not contain speech.
I won't go into detail about processing speed here, as it was already just over 1:1 on a Macbook Air with an M2 processor in terms of processing speed to video length, and is considerably faster on an Nvidia graphics card with CUDA, depending on the model, provided the software you're using supports it. With an Nvidia RTX 4060 Ti it was at around 5:1.
Regrouping Segments
Following best practices for subtitling alone does not ensure that the subtitles will be perfectly readable. In addition to the length and number of lines, it is important that the segments match the structure of the sentences. For example, it is difficult to read if the subtitle segment contains only the last words of a sentence and then a new sentence begins immediately.

I haven't found any technology that reliably recognizes sentence structure; perhaps an additional AI solution that can process linguistic syntax could be used for this. However, I imagine that it would be difficult to find a perfect solution, since in addition to sentence structure, length restrictions also need to be taken into account. So my goal was to at least achieve a noticeable improvement in readability.
Using a combination of different algorithms, the readability could be significantly improved by regrouping the segments with more natural boundaries, as shown in the screenshot below. Of course, you can never completely avoid punctuation within segments.

Further Improvements
Further improvements can be made in the areas of timestamp accuracy and hallucinations.
Timestamp Accuracy
There are several technical approaches that can be used to improve the quality of timestamps. Although the number of videos I have processed and subjectively compared is not sufficient to make a representative statement, I have tried several solutions.
- I was not satisfied with the results of using a wav2vec model as an additional neural network.
- Another approach, using the probabilities of timestamp tokens estimated by the Whisper model after predicting each word token, also did not seem to produce really reliable results.
- Whisper itself produced acceptable timestamps that had good timings in most cases, but were sometimes off.
- The best timings in my tests were achieved by a solution that applied Dynamic Time Warping (DTW) to cross-attention weights. I felt that the results were even more accurate.
Reduction of Hallucinations
As mentioned above, I found large-v2 to hallucinate less than large-v3. Pre-processing the audio track prior to processing with Whisper should further reduce hallucinations. For example, Demucs can be used to isolate vocals. Voice Activity Detection (VAD) can also be used to prevent audio without speech from being processed by the model.
OpenAI Whisper vs. YouTube
So let's compare the results with what YouTube currently offers. The following screenshot shows the automatically generated YouTube subtitles for the example video compared two post-processed Whisper subtitles on the right. I think there is no question about readability or error rates in this comparison.

Key Lessons
I firmly believe that this approach, while not 100% perfect, could already be a huge step towards accessibility today. Of course, such automated transcriptions cannot meet journalistic standards without human oversight. On the other hand, I appreciate YouTube's approach of offering automatically generated subtitles to enrich content that otherwise lacks subtitles.
And I think one thing is obvious: the subtitles I was able to create in my tests with OpenAI Whisper (and additional post-processing) beat YouTube's automatically generated subtitles by far.
Advantages
- Open source (MIT License)
- Runs locally
- Fast implementations for CUDA are available
- Great transcription quality (error rates about 5% for German)
- Timestamp accuracy is acceptable, other Whisper-based solutions may provide even better results
Disadvantages
- Subtitle segments need to be regrouped in post for better readability
- The audio and transcription language is detected at the beginning or given as a parameter. Changing languages within the audio source (e.g. English parts in an otherwise German video) are not transcribed correctly. Splitting the audio by language should work as a workaround.
- Strong accents or unclear pronunciation lead to incorrect transcription
- When multiple speakers speak at the same time, the texts blend together.
